

IA collaborative en équipe : que faire pour que ça marche ?
Résumé de l'article
📖 10 min de lectureL'IA individuelle scale mal en équipe : contextes silotés, mémoires non partagées, incohérences multipliées. Une agence de 5 personnes perd ~82h/mois en reconstruction de contexte (4 125€ de valeur évaporée). La solution est architecturale : mémoire vectorielle partagée (pgvector) avec gestion granulaire des accès par rôle, où l'IA se souvient du projet — pas juste de l'utilisateur. La collaboration augmentée transforme l'IA d'outil individuel de productivité en infrastructure collective de décision.
Points clés :
- L'IA individuelle régresse quand l'équipe grandit — trois patterns toxiques : le messager (copier-coller Slack), le contexte fantôme (versions divergentes), la régression (moins utile à plus de personnes)
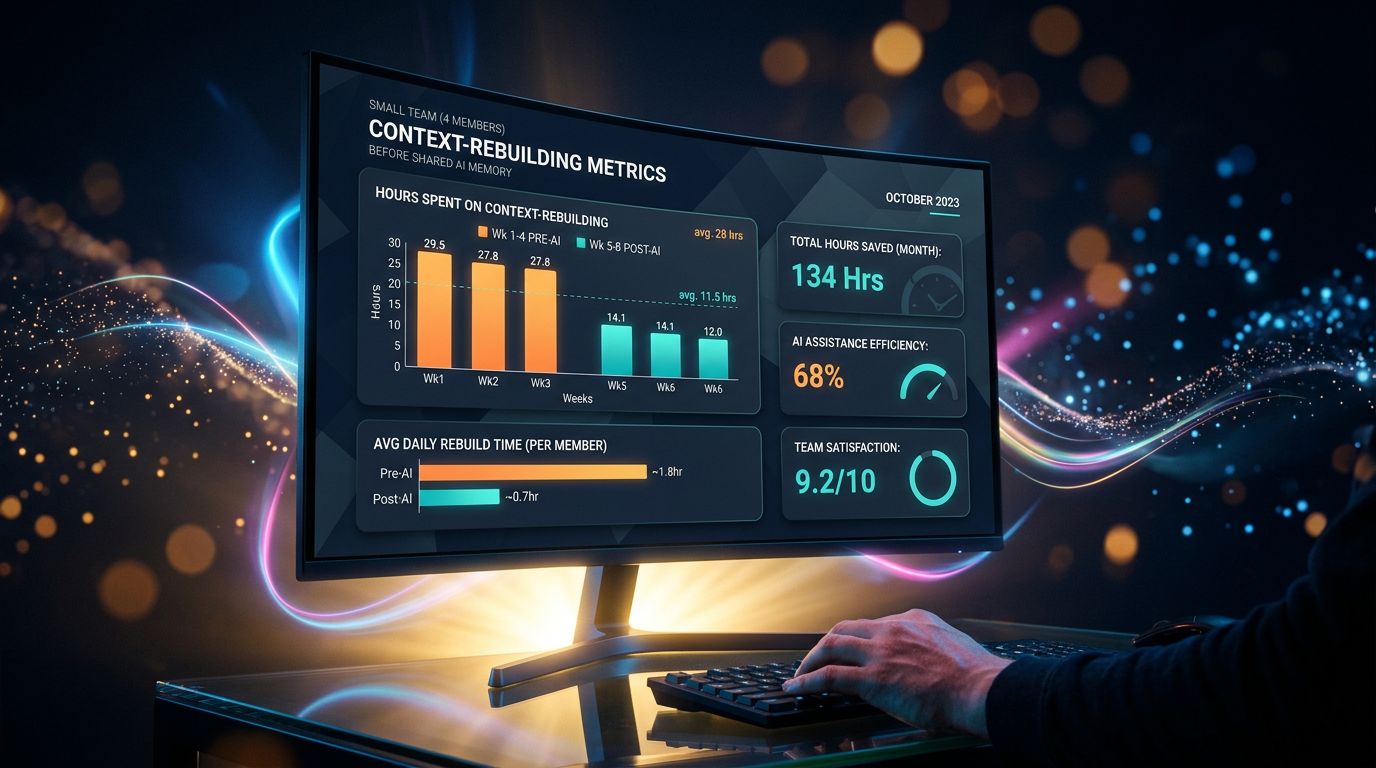
- Une agence de 5 personnes perd 82,5 heures/mois en reconstruction de contexte (45 min/jour × 5 personnes × 22 jours = 4 125€/mois de valeur évaporée)
- La vraie mémoire partagée stocke dans un espace vectoriel commun accessible à tous les membres autorisés — l'IA se souvient du projet, pas de l'utilisateur
- La gestion granulaire des accès (owner, collaborator, viewer) doit s'appliquer à la mémoire IA elle-même, pas seulement aux fichiers — contexte filtré selon le rôle
- Le shift clé : passer de l'IA comme outil individuel de productivité à l'IA comme infrastructure collective de décision — 'on se réunit pour décider où on va, pas pour se rappeler où on en est'
Quand votre équipe grandit, votre IA régresse : le paradoxe de la collaboration augmentée
Il y a un moment précis où tout se grippe.
Vous étiez solo. Votre assistant IA connaissait vos clients, vos projets, votre façon de travailler. Puis vous avez recruté. Un collaborateur. Deux. Une petite équipe. Et là, l’outil qui vous faisait gagner 8h par semaine est devenu un boulet collectif.
Personne ne sait ce que l’autre a demandé à l’IA. Chaque session repart de zéro. Le contexte se perd entre les mains. Et vous vous retrouvez à ré-expliquer les mêmes briefs, les mêmes clients, les mêmes contraintes — non plus à l’IA, mais à vos propres collaborateurs qui tentent de la faire fonctionner.
L’IA individuelle scale mal. Et presque personne n’en parle.
Le mythe de l’IA collaborative “prête à l’emploi”
Tout le monde vend de la collaboration IA. Les slides sont belles. Les démos sont fluides. “Travaillez ensemble avec l’IA” — phrase passe-partout que vous avez lue sur dix landing pages différentes cette semaine.
Voici ce qu’on ne vous dit jamais : la majorité des outils IA ont été conçus pour un utilisateur individuel, puis ont ajouté une couche “équipe” par-dessus. Comme coller un post-it “multi-joueurs” sur un jeu solo.
Le résultat ? Des contextes qui ne se partagent pas. Des mémoires qui restent silotées par compte. Des assistants qui connaissent parfaitement les habitudes de leur utilisateur — et rien des habitudes de ses collègues.
Mon analyse révèle trois patterns récurrents dans les équipes qui tentent de “scaler” leur usage IA :
Le pattern du messager. Un collaborateur obtient une bonne réponse. Il la copie-colle dans Slack pour que les autres en profitent. L’IA n’a rien appris. L’équipe non plus.
Le pattern du contexte fantôme. Chaque membre brief l’IA avec sa version du projet. Trois versions différentes d’un même client circulent dans les sessions. Incohérences garanties.
Le pattern de la régression. Plus l’équipe grandit, moins l’IA est utile. Paradoxe total. Exactement l’inverse de ce que vous espériez.
Ce que “mémoire partagée” veut vraiment dire

Parlons technique — mais clairement.
La mémoire d’un assistant IA, dans la plupart des implémentations actuelles, est liée à une session ou à un utilisateur. Quand votre collaboratrice Malia brief Nova sur le client Bertrand & Associés, cette information reste dans sa session. Quand Thomas travaille sur le même dossier deux heures plus tard, il repart de zéro.
Ce n’est pas un bug. C’est une limite architecturale que peu d’outils ont réellement résolue.
La vraie mémoire partagée, ça ressemble à ça : un espace vectoriel commun (pgvector, par exemple) où chaque interaction, chaque donnée client, chaque préférence de projet est stockée et accessible à tous les membres autorisés de l’équipe. L’IA ne se souvient pas “de vous” — elle se souvient “du projet”.
“La collaboration n’est pas une fonctionnalité qu’on ajoute. C’est une contrainte qu’on intègre dès l’architecture.” — principe fondateur de Nova-Mind
La différence est fondamentale. Dans le premier cas, vous gérez des silos intelligents. Dans le second, vous construisez une intelligence collective.
Voici ce que ça change concrètement pour une agence de 4 personnes :
- Quand un client appelle et tombe sur n’importe qui dans l’équipe, cette personne a accès au contexte complet du dossier — pas juste aux notes dans un Google Doc, mais à l’historique des interactions IA, des décisions prises, des contraintes exprimées.
- Quand quelqu’un quitte l’équipe, la mémoire du projet reste. Pas dans sa tête. Dans le système.
- Quand vous onboardez un nouveau collaborateur, il ne passe pas deux semaines à “rattraper le contexte”. Il pose des questions à l’IA. Elle répond avec tout ce qu’elle sait du projet.
C’est ça, la collaboration augmentée. Pas des emojis en temps réel.
Le vrai coût du contexte perdu
Faisons le calcul. Pas de la théorie — des chiffres.
Une agence digitale de 5 personnes. Chaque collaborateur passe en moyenne 45 minutes par jour à “reconstruire le contexte” : retrouver des briefs, re-briefer l’IA, chercher des décisions passées dans des fils Slack, relire des emails pour comprendre où en est un client.
45 minutes × 5 personnes × 22 jours ouvrés = 82,5 heures perdues par mois.
À un coût horaire moyen de 50€ pour une agence, c’est 4 125€ de valeur évaporée chaque mois. Pas en salaires directs — en capacité productive non réalisée.
Et ce chiffre ne compte pas le coût invisible : les erreurs de contexte. Le devis envoyé avec les mauvaises hypothèses parce que personne n’avait vu la note de la semaine dernière. La réponse client incohérente parce que deux personnes avaient des versions différentes du brief.
Retournons la situation : si votre stack IA vous coûte 200€/mois et vous fait récupérer 30h d’équipe, vous êtes largement gagnant. Si elle vous coûte 200€/mois et ajoute 10h de friction collective, vous payez pour vous ralentir.
Collaboration granulaire : qui voit quoi, qui fait quoi
Voici où ça devient croustillant.
La mémoire partagée règle le problème du contexte. Mais elle crée un nouveau problème : tout le monde voit tout ? Vraiment ?
Non. Et c’est là que la gestion des accès devient stratégique.
Une vraie plateforme de collaboration augmentée distingue les niveaux d’accès au contexte IA. Pas juste “admin / membre / visiteur” sur les fichiers. Mais sur la mémoire elle-même. Sur les clients. Sur les projets. Sur ce que l’IA peut révéler à qui.
Exemple concret : vous avez un client sensible. Contrat en cours de renégociation. Vous ne voulez pas que le stagiaire qui gère les réseaux sociaux ait accès aux discussions stratégiques sur ce compte. Mais vous voulez qu’il puisse utiliser l’IA pour générer du contenu aligné avec la charte du client.
Deux niveaux d’accès. Même outil. Même IA. Contexte filtré selon le rôle.
C’est ce que Nova-Mind appelle la gestion granulaire des accès — owner, collaborator, viewer — appliquée non pas juste aux fichiers, mais à l’intelligence même du système.
L’expérience m’a appris que c’est cette couche-là que les équipes négligent au moment de choisir leur outil. Elles regardent les features. Elles testent l’IA. Elles oublient de demander : “Qui peut voir quoi dans la mémoire du système ?”
Trois signaux que votre stack IA n’est pas prête pour votre équipe
Pas besoin d’audit long. Trois questions suffisent.
Signal 1 : Le test du nouveau collaborateur. Combien de temps faut-il à quelqu’un qui rejoint votre équipe pour être opérationnel sur un projet existant ? Si la réponse dépasse une semaine, votre contexte est dans les têtes — pas dans le système. L’IA ne peut pas aider.
Signal 2 : Le test de la question client. Si votre client appelle et tombe sur n’importe qui dans l’équipe, cette personne peut-elle répondre sans chercher ? Sans demander “je te rappelle” ? Si non, votre mémoire projet est fragmentée.
Signal 3 : Le test de la cohérence IA. Demandez à deux membres de votre équipe de poser la même question à votre assistant IA sur un même client. Obtenez-vous la même réponse ? Ou deux versions différentes selon les sessions de chacun ?
Si vous avez répondu “non” à au moins deux de ces questions, votre IA est encore un outil individuel déguisé en solution d’équipe.
Ce que ça change quand ça fonctionne vraiment
Mon obsession du détail révèle quelque chose que les benchmarks ne capturent pas : la vraie valeur de la collaboration augmentée n’est pas dans les heures récupérées. Elle est dans la qualité des décisions.
Quand tout le monde travaille avec le même contexte, les décisions s’alignent naturellement. Pas besoin de réunion de “mise à jour”. Pas besoin de document de synthèse que personne ne lit. L’IA porte le contexte. L’équipe porte la créativité et le jugement.
Une agence qui utilise Nova-Mind avec une équipe de 4 personnes a décrit ça comme : “On a arrêté de se réunir pour se rappeler où on en est. On se réunit pour décider où on va.”
C’est le shift.
Passer de l’IA comme outil individuel de productivité à l’IA comme infrastructure collective de décision. Ce n’est pas la même chose. Ce n’est pas le même investissement. Ce n’est pas le même ROI.
Et ça commence par une question architecturale simple : est-ce que votre mémoire IA est partageable ? Pas en théorie. En pratique. Maintenant.
Trois choses à faire cette semaine
1. Auditez votre contexte actuel. Listez les 5 projets ou clients les plus importants de votre équipe. Pour chacun, demandez : où vit le contexte ? Dans des têtes ? Dans des docs épars ? Dans des sessions IA individuelles ? Le diagnostic est souvent brutal — et nécessaire.
2. Testez le test de cohérence. Prenez un projet actif. Demandez à deux collaborateurs de poser la même question à votre outil IA. Comparez les réponses. Si elles divergent, vous avez votre réponse sur l’état de votre mémoire partagée.
3. Posez la bonne question avant le prochain outil. Avant d’évaluer une nouvelle solution IA pour votre équipe, posez cette question unique : “Est-ce que la mémoire est partagée entre les membres, avec gestion des accès granulaire ?” Si le commercial hésite, passez votre chemin.
La vraie question n’est pas “quelle IA ?” mais “quelle architecture ?”
Vous pouvez avoir le meilleur modèle de langage du marché. Si la mémoire est silotée par utilisateur, votre équipe travaillera toujours en parallèle — jamais vraiment ensemble.
La collaboration augmentée n’est pas un marketing. C’est une contrainte technique résolue ou non. Et la résolution coûte moins cher que vous ne le pensez — 39€/mois pour commencer, contre des milliers d’euros de friction collective par an.
Nova-Mind a été conçu avec cette contrainte au cœur : mémoire persistante partagée, gestion des accès par rôle, contexte projet accessible à toute l’équipe via les 36 outils MCP. Pas une feature ajoutée après coup. Une décision d’architecture prise dès le départ.
Si votre équipe grandit et que votre IA régresse, ce n’est pas un problème d’IA. C’est un problème d’architecture.
Et ça, ça se change.
Testez Nova-Mind avec votre équipe — 14 jours pour voir si le contexte partagé change vraiment votre façon de travailler. Pas de carte bleue au démarrage. Juste la réponse à votre test de cohérence.
Partager cet article
Réseaux sociaux
Analyser avec l'IA

Charles Annoni
Chef de projetCharles Annoni accompagne les entreprises dans leur développement sur le web depuis 2008.









