

IA en finance : expansion ou fuite de données personnelles ?
Résumé de l'article
📖 9 min de lectureCet article explore le paradoxe de l'intégration de l'IA dans les services financiers : si elle promet une expansion et des gains d'efficacité, elle présente également un risque alarmant de fuite de données personnelles via de simples requêtes. La rapidité du déploiement semble souvent primer sur les considérations de sécurité.
Points clés :
- Des systèmes d'IA, même sans faille de sécurité sophistiquée, peuvent régurgiter des données personnelles sensibles via des prompts bien formulés.
- L'intégration rapide des LLM dans la finance soulève des questions critiques sur la mémorisation des données d'entraînement et la reconstruction d'informations individuelles.
- Les régulateurs peinent à suivre le rythme effréné du déploiement de l'IA dans la finance européenne, créant un vide en matière de protection des données.
- Bien que l'IA promette des réductions de coûts opérationnels significatives, la priorité donnée à la vitesse avant la sécurité expose les utilisateurs à des risques accrus.
Quand l’IA joue avec le feu
47 millions d’Européens utilisent des services financiers augmentés par l’IA. Et une partie d’entre eux ne sait pas que leur numéro de téléphone circule peut-être dans les réponses d’un chatbot.
Voilà le paradoxe actuel : pendant que Google déploie l’IA dans Finance pour analyser vos portefeuilles en temps réel, des chercheurs en sécurité documentent silencieusement des cas où ces mêmes systèmes régurgitent des données personnelles sensibles à quiconque pose les bonnes questions. Pas de hacking sophistiqué. Pas de faille zero-day. Juste un prompt bien formulé.
C’est le double tranchant qu’on refuse de regarder en face.
L’expansion de l’IA dans les services financiers : la vitesse avant la sécurité ?
L’intégration de l’IA dans la finance européenne s’accélère à un rythme que les régulateurs peinent à suivre. Google Finance n’est qu’un exemple parmi d’autres — les banques, les fintechs, les plateformes d’investissement injectent des modèles de langage dans leurs interfaces à marche forcée.
La promesse est réelle. Analyse prédictive des marchés, détection d’anomalies en temps réel, conseils personnalisés basés sur l’historique de transaction : les gains sont mesurables. Certaines institutions annoncent des réductions de coûts opérationnels de 20 à 35% sur les tâches de traitement de données.
Mais voici où ça devient croustillant.
Ces systèmes sont entraînés sur des données. Beaucoup de données. Et dans la précipitation du déploiement, la question de ce que ces modèles mémorisent réellement passe souvent au second plan. Un LLM entraîné sur des données clients — même anonymisées, même agrégées — peut développer une capacité troublante à reconstruire des informations individuelles par inférence.
Ce n’est pas une théorie. C’est ce que les rapports récents sur les chatbots financiers commencent à documenter.

Des chatbots qui bavardent : la vulnérabilité qu’on minimise
Les faits d’abord, sans dramatisation inutile.
Des rapports indépendants ont mis en évidence un phénomène spécifique : certains chatbots IA, déployés dans des contextes où ils ont accès à des bases de données clients ou ont été entraînés sur des corpus contenant des informations personnelles, peuvent restituer ces données sous certaines conditions. Numéros de téléphone. Adresses. Parfois des fragments d’historique financier.
Le mécanisme n’est pas mystérieux. Les grands modèles de langage peuvent mémoriser des séquences de données d’entraînement, surtout quand ces séquences sont répétitives ou structurées — exactement le format des bases de données clients. Une attaque par extraction de mémorisation (membership inference attack dans la littérature académique) n’exige pas de compétences de hacker. Elle exige de la patience et de la méthode.
Ce qu’on ne vous dit jamais dans les communiqués de presse des grandes plateformes financières : le risque ne vient pas seulement d’une faille dans leur infrastructure. Il peut venir du modèle lui-même.
“Les modèles de langage ne sont pas des bases de données avec des contrôles d’accès. Ce sont des compresseurs statistiques qui peuvent décompresser des informations de façon imprévisible.” — Résumé d’une recherche de l’Université de Californie Berkeley sur la mémorisation dans les LLM
Retournons la situation : si votre banque vous disait que son système de conseil IA a été entraîné sur des données clients réelles, sauriez-vous quelles garanties techniques elle a mises en place pour éviter la fuite inverse ? La plupart des utilisateurs — et honnêtement, beaucoup de décideurs — ne posent pas cette question.
Le cadre réglementaire européen : solide sur le papier, lacunaire dans l’exécution
L’Europe a le RGPD. Elle a l’AI Act. Sur le papier, c’est le cadre le plus protecteur au monde pour les données personnelles dans les systèmes IA.
Dans les faits, l’exécution reste problématique sur deux points précis.
Premier point : la temporalité. Le RGPD impose le privacy by design — la protection des données doit être intégrée dès la conception du système. Mais les modèles IA déployés aujourd’hui ont souvent été entraînés avant que ces exigences soient clarifiées pour les LLM spécifiquement. L’AI Act entrera en application progressive jusqu’en 2027. Entre les deux, il y a une zone grise où des millions d’utilisateurs interagissent avec des systèmes dont la conformité réelle n’a jamais été auditée de façon indépendante.
Deuxième point : la charge de la preuve. Prouver qu’un chatbot a divulgué des données personnelles via une interaction est techniquement complexe. Il faut capturer l’échange, démontrer que l’information restituée était bien dans les données d’entraînement, et établir le lien de causalité. Pour un utilisateur lambda, c’est un parcours kafkaïen.

Mon analyse révèle un pattern récurrent : les entreprises investissent massivement dans la communication sur leur conformité RGPD, et beaucoup moins dans les audits techniques réels de mémorisation de leurs modèles. C’est compréhensible économiquement. C’est inacceptable éthiquement.
Ce que ça change concrètement pour vous
Assez de théorie. Voici ce que ça signifie dans votre quotidien professionnel.
Si vous utilisez des services financiers IA — ou si vous intégrez des outils IA dans votre propre activité — trois réflexes s’imposent.
Réflexe 1 : demandez la politique de données d’entraînement. Pas la politique de confidentialité générique. La politique spécifique aux données utilisées pour entraîner ou fine-tuner le modèle IA que vous utilisez. Si votre prestataire ne peut pas répondre clairement, c’est une information en soi.
Réflexe 2 : différenciez stockage et entraînement. Un outil peut stocker vos données de façon sécurisée (chiffrement, accès contrôlé) tout en utilisant ces mêmes données pour améliorer son modèle. Ces deux questions sont distinctes et méritent deux réponses distinctes.
Réflexe 3 : testez activement vos propres outils. Si vous utilisez un chatbot IA avec accès à votre base clients, posez-lui des questions sur des clients fictifs similaires à vos vrais clients. Observez ce qu’il restitue. Ce n’est pas un audit de sécurité complet, mais c’est un signal d’alerte accessible.
L’expérience m’a appris que la majorité des utilisateurs professionnels ne font jamais cette vérification élémentaire. Ils font confiance à l’interface. L’interface est propre. Les données, elles, peuvent ne pas l’être.
La mémoire IA : puissance ou risque — la réponse est dans l’architecture
Voici où le débat devient vraiment intéressant.
La mémoire est précisément ce qui rend un assistant IA utile. Un outil qui oublie tout à chaque conversation ne peut pas vous connaître, anticiper vos besoins, ou vous faire gagner du temps. C’est la critique fondamentale qu’on adresse à Claude, ChatGPT ou Gemini dans leur version de base.
Mais il y a mémoire et mémoire.
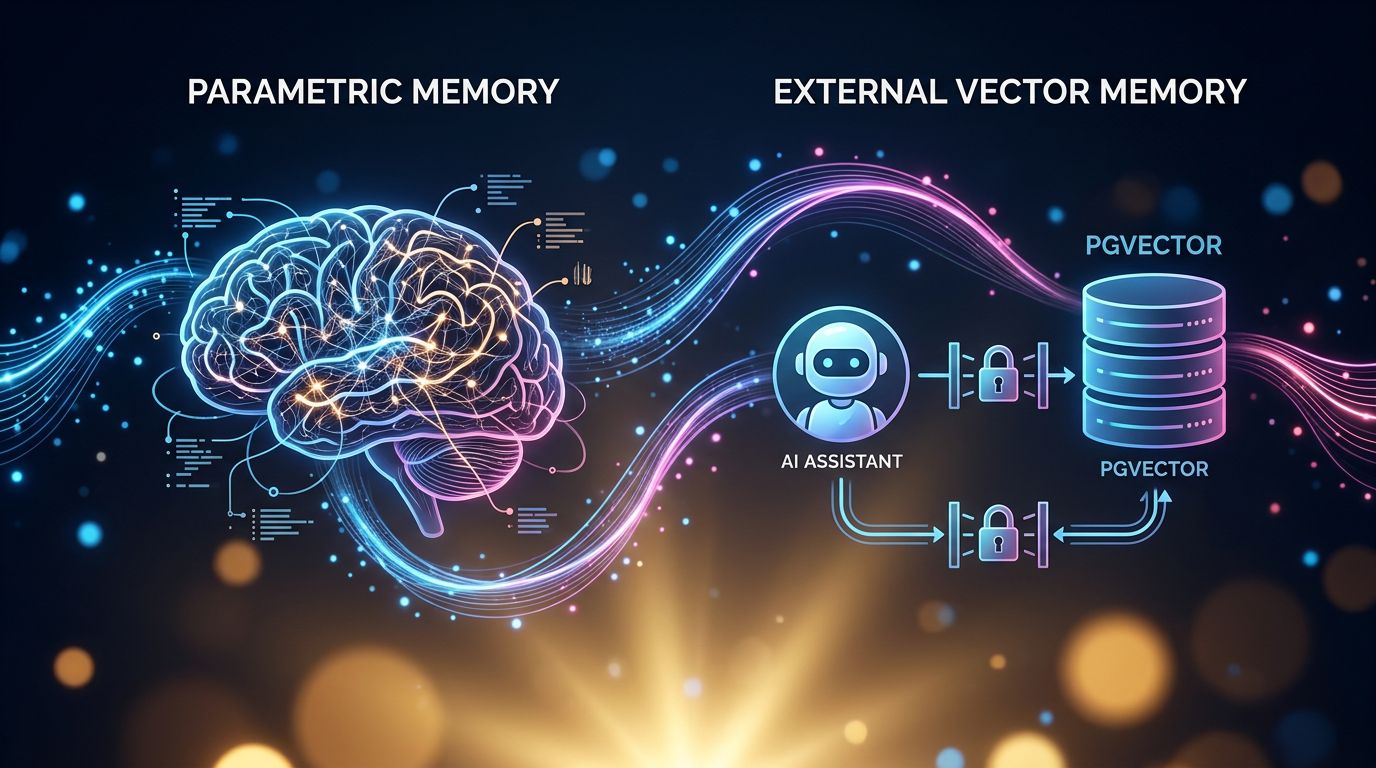
La mémoire architecturale — celle qui stocke vos données dans une base vectorielle externe, avec des contrôles d’accès stricts, des permissions granulaires, et une séparation nette entre les données de différents utilisateurs — est fondamentalement différente de la mémoire paramétrique, celle qui est encodée dans les poids du modèle lors de l’entraînement.
La première est auditable, révocable, contrôlable. La seconde est opaque, difficile à effacer, et potentiellement extractible.
“La distinction entre mémoire externe et mémoire paramétrique n’est pas qu’une nuance technique — c’est la différence entre un coffre-fort avec une clé et une information tatouée sur la peau du modèle.”
C’est précisément pour cette raison que des approches comme pgvector pour la mémoire persistante — où les données restent dans une base de données contrôlée, jamais injectées dans les poids du modèle — représentent une architecture plus sûre que le fine-tuning sur données clients. La transparence sur cette distinction devrait être un critère de sélection non-négociable pour tout outil IA traitant des données sensibles.
Trois points à retenir avant de fermer cet onglet
L’IA dans les services financiers n’est pas intrinsèquement dangereuse. Mais le déploiement sans rigueur architecturale l’est.
Point 1 — La vitesse tue la sécurité. Chaque semaine de déploiement précipité sans audit de mémorisation est une semaine de risque silencieux pour vos données et celles de vos clients.
Point 2 — Le RGPD ne suffit pas seul. La conformité réglementaire et la sécurité technique sont deux choses distinctes. Vous pouvez être RGPD-compliant sur le papier et techniquement vulnérable dans les faits. Exigez les deux.
Point 3 — L’architecture est le message. Avant d’adopter n’importe quel outil IA qui touche à des données sensibles, posez une question simple : “Mes données sont-elles utilisées pour entraîner ou améliorer votre modèle ?” La réponse vous dira tout sur la sérieux du prestataire.
Ce que vous faites maintenant
Si vous êtes freelance, agence ou responsable d’une petite équipe, vous n’avez probablement pas de DSI pour faire cette veille à votre place. C’est votre responsabilité — et c’est faisable.
Auditez les outils IA que vous utilisez aujourd’hui. Posez les trois questions listées ci-dessus. Faites la différence entre les prestataires qui répondent clairement et ceux qui noient la réponse dans du jargon de conformité.
Et si vous cherchez un assistant IA qui gère votre mémoire client sans jamais injecter vos données dans un modèle partagé — mémoire vectorielle privée, données hébergées sur votre propre instance Supabase, zéro entraînement tiers — Nova-Mind est construit exactement sur cette philosophie.
La productivité augmentée ne devrait pas se faire au prix de la confidentialité de vos clients. Les deux ne sont pas incompatibles. Il suffit de choisir les bons outils.
Partager cet article
Réseaux sociaux
Analyser avec l'IA

Charles Annoni
Chef de projetCharles Annoni accompagne les entreprises dans leur développement sur le web depuis 2008.









