

AI in finance: expansion or personal data leak?
Article Summary
📖 9 min readThis article explores the paradox of AI integration in financial services: while it promises expansion and efficiency gains, it also presents an alarming risk of personal data leakage through simple queries. The speed of deployment often seems to take priority over security considerations.
Key Points:
- AI systems, even without sophisticated security flaws, can regurgitate sensitive personal data through well-crafted prompts.
- The rapid integration of LLMs in finance raises critical questions about training data memorization and the reconstruction of individual information.
- Regulators are struggling to keep pace with the frantic deployment of AI in European finance, creating a gap in data protection.
- While AI promises significant operational cost reductions, prioritizing speed over security exposes users to increased risks.
When AI Plays with Fire
47 million Europeans use financial services augmented by AI. And some of them have no idea that their phone number might be circulating in a chatbot’s responses.
That’s the current paradox: while Google deploys AI in Finance to analyze portfolios in real time, security researchers are quietly documenting cases where these same systems regurgitate sensitive personal data to anyone who asks the right questions. No sophisticated hacking. No zero-day exploit. Just a well-crafted prompt.
This is the double-edged sword nobody wants to look at directly.
AI Expansion in Financial Services: Speed Before Security?
The integration of AI into European finance is accelerating at a pace regulators are struggling to follow. Google Finance is just one example — banks, fintechs, and investment platforms are injecting language models into their interfaces at full speed.
The promise is real. Predictive market analysis, real-time anomaly detection, personalized advice based on transaction history: the gains are measurable. Some institutions report operational cost reductions of 20 to 35% on data processing tasks.
But here is where things get interesting.
These systems are trained on data. A lot of data. And in the rush to deploy, the question of what these models actually memorize often takes a back seat. An LLM trained on customer data — even anonymized, even aggregated — can develop a troubling ability to reconstruct individual information through inference.
This is not a theory. It is what recent reports on financial chatbots are beginning to document.

Chatbots That Talk Too Much: The Vulnerability We Downplay
Facts first, without unnecessary dramatization.
Independent reports have highlighted a specific phenomenon: certain AI chatbots, deployed in contexts where they have access to customer databases or have been trained on corpora containing personal information, can disclose that data under certain conditions. Phone numbers. Addresses. Sometimes fragments of financial history.
The mechanism is not mysterious. Large language models can memorize sequences from training data, especially when those sequences are repetitive or structured — exactly the format of customer databases. A memorization extraction attack (known in academic literature as a membership inference attack) requires no hacking skills. It requires patience and method.
What the press releases from major financial platforms never tell you: the risk does not come only from a flaw in their infrastructure. It can come from the model itself.
“Language models are not databases with access controls. They are statistical compressors that can decompress information in unpredictable ways.” — Summary of research from the University of California Berkeley on memorization in LLMs
Turn the situation around: if your bank told you that its AI advisory system was trained on real customer data, would you know what technical guarantees it put in place to prevent reverse leakage? Most users — and honestly, many decision-makers — never ask that question.
The European Regulatory Framework: Solid on Paper, Lacking in Execution
Europe has the GDPR. It has the AI Act. On paper, it is the most protective framework in the world for personal data in AI systems.
In practice, enforcement remains problematic on two specific points.
First point: timing. The GDPR mandates privacy by design — data protection must be embedded from the very design of the system. But AI models deployed today were often trained before these requirements were clarified specifically for LLMs. The AI Act will be applied progressively until 2027. In between, there is a grey zone where millions of users interact with systems whose actual compliance has never been independently audited.
Second point: burden of proof. Proving that a chatbot disclosed personal data through an interaction is technically complex. You need to capture the exchange, demonstrate that the information disclosed was indeed in the training data, and establish causation. For an ordinary user, this is a kafkaesque ordeal.

My analysis reveals a recurring pattern: companies invest massively in communicating about their GDPR compliance, and far less in actual technical audits of their models’ memorization. This is economically understandable. Ethically, it is unacceptable.
What This Concretely Changes for You
Enough theory. Here is what this means in your professional day-to-day.
If you use AI-powered financial services — or if you integrate AI tools into your own business — three reflexes are essential.
Reflex 1: ask for the training data policy. Not the generic privacy policy. The specific policy covering the data used to train or fine-tune the AI model you are using. If your provider cannot answer clearly, that itself is information.
Reflex 2: distinguish storage from training. A tool can store your data securely (encryption, controlled access) while also using that same data to improve its model. These are two distinct questions that deserve two distinct answers.
Reflex 3: actively test your own tools. If you use an AI chatbot with access to your customer database, ask it questions about fictional customers similar to your real ones. Observe what it returns. This is not a complete security audit, but it is an accessible warning signal.
Experience has taught me that the vast majority of professional users never perform this basic check. They trust the interface. The interface looks clean. The data, however, may not be.
AI Memory: Power or Risk — the Answer Lies in Architecture
This is where the debate gets genuinely interesting.
Memory is precisely what makes an AI assistant useful. A tool that forgets everything at the end of each conversation cannot know you, anticipate your needs, or save you time. That is the fundamental criticism leveled at Claude, ChatGPT, or Gemini in their base versions.
But there is memory and there is memory.
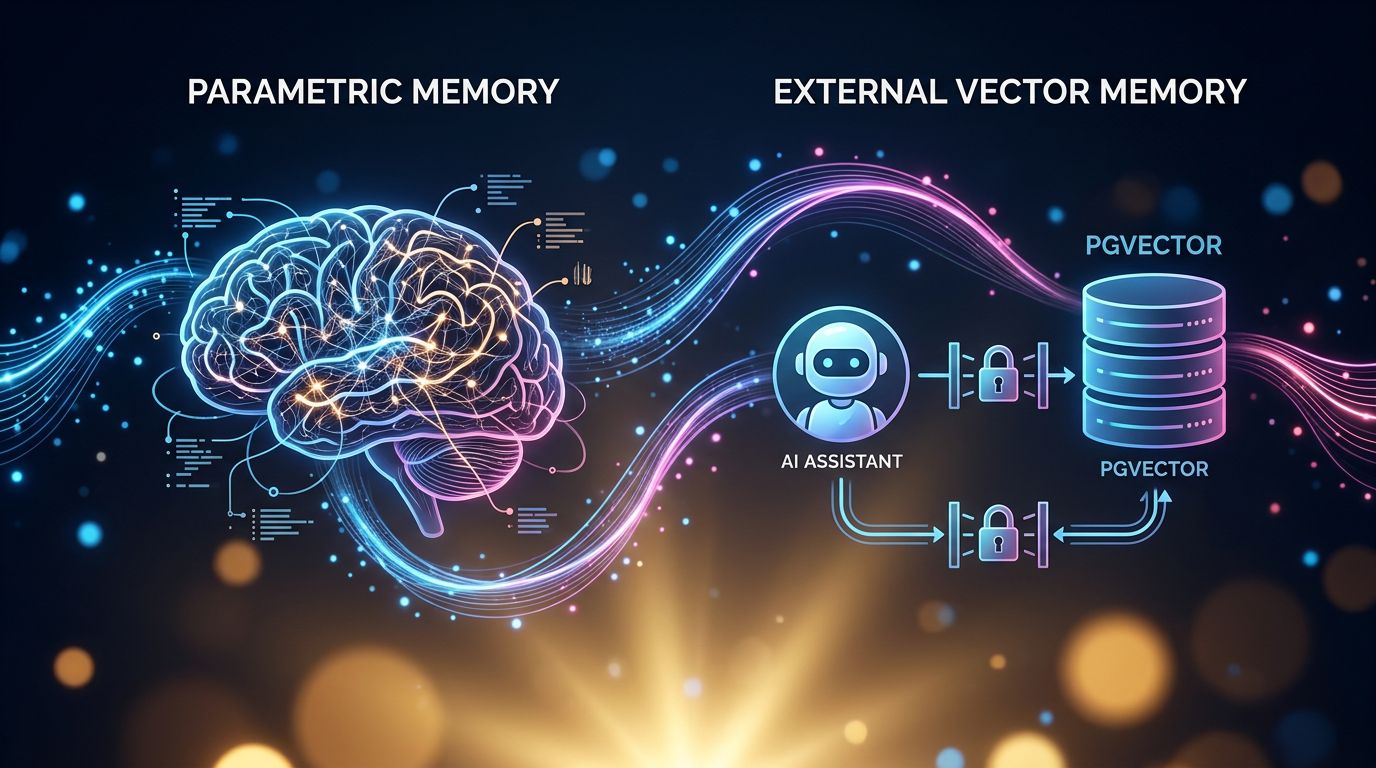
Architectural memory — the kind that stores your data in an external vector database, with strict access controls, granular permissions, and a clear separation between different users’ data — is fundamentally different from parametric memory, which is encoded into the model’s weights during training.
The first is auditable, revocable, controllable. The second is opaque, difficult to erase, and potentially extractable.
“The distinction between external memory and parametric memory is not merely a technical nuance — it is the difference between a safe with a key and information tattooed on the model’s skin.”
This is precisely why approaches like pgvector for persistent memory — where data stays in a controlled database, never injected into the model’s weights — represent a safer architecture than fine-tuning on customer data. Transparency about this distinction should be a non-negotiable selection criterion for any AI tool handling sensitive data.
Three Points to Take Away Before You Close This Tab
AI in financial services is not inherently dangerous. But deployment without architectural rigor is.
Point 1 — Speed kills security. Every week of rushed deployment without a memorization audit is a week of silent risk for your data and that of your clients.
Point 2 — GDPR alone is not enough. Regulatory compliance and technical security are two distinct things. You can be GDPR-compliant on paper and technically vulnerable in practice. Demand both.
Point 3 — Architecture is the message. Before adopting any AI tool that touches sensitive data, ask one simple question: “Is my data used to train or improve your model?” The answer will tell you everything about how serious the provider is.
What You Do Now
If you are a freelancer, an agency, or managing a small team, you probably do not have a CTO to handle this monitoring for you. This is your responsibility — and it is manageable.
Audit the AI tools you use today. Ask the three questions listed above. Distinguish between providers who answer clearly and those who bury the response in compliance jargon.
And if you are looking for an AI assistant that manages your customer memory without ever injecting your data into a shared model — private vector memory, data hosted on your own Supabase instance, zero third-party training — Nova-Mind is built on exactly this philosophy.
Enhanced productivity should not come at the cost of your clients’ privacy. The two are not incompatible. You just need to choose the right tools.
Share this article
Social networks
Analyze with AI

Charles Annoni
Front-End Developer and TrainerCharles Annoni has been helping companies with their web development since 2008. He is also a trainer in higher education.









