

Mémoire IA : pourquoi Claude oublie tout (et comment j'ai réglé ce problème)
Résumé de l'article
📖 10 min de lectureCet article explique pourquoi les LLM n'ont aucune mémoire entre les sessions — un choix architectural, pas un bug — et comment construire une couche de persistance avec pgvector et des embeddings vectoriels. Il détaille le protocole MCP qui permet à Claude Desktop d'interroger cette mémoire en temps réel, chiffre les gains concrets (4h/semaine récupérées), et liste les trois erreurs classiques qui font échouer les tentatives DIY de mémoire IA.
Points clés :
- Les utilisateurs d'IA professionnels perdent en moyenne 12 à 18 minutes par jour à reconstruire le contexte — soit plus de 75 heures par an
- pgvector + embeddings permettent une recherche sémantique (par sens, pas par mots-clés) qui injecte le bon contexte au bon moment
- Le protocole MCP transforme Claude Desktop d'un chatbot en collaborateur contextualisé avec 36 outils intégrés
- Sur 10 clients actifs, la mémoire persistante économise environ 4 heures par semaine soit 2 jours de travail par mois
- Les trois erreurs fatales : stocker sans structurer, négliger la mise à jour, confondre mémoire vectorielle et surcharge de contexte
Vous en avez marre de ré-expliquer qui est votre client
Chaque lundi matin. Même scénario. Vous ouvrez Claude, vous posez une question sur un projet en cours — et vous réalisez que vous devez tout réexpliquer depuis le début. Le client, le contexte, les contraintes, le ton de communication. Encore.
Ce n’est pas un bug. C’est une limite architecturale fondamentale des LLM. Claude, ChatGPT, Gemini — aucun d’eux ne se souvient de vous d’une session à l’autre. Zéro. Chaque conversation repart de zéro, comme si vous vous rencontriez pour la première fois.
Pour un freelance qui gère 15 clients actifs, ou une agence avec 40 projets simultanés, c’est une friction réelle. Mesurable. Coûteuse.
Voici ce que j’ai observé : en moyenne, les utilisateurs d’IA professionnels passent 12 à 18 minutes par jour à reconstruire le contexte dans leurs conversations. Sur une semaine, c’est 1h30 minimum. Sur un an ? Plus de 75 heures perdues à expliquer ce que l’IA aurait dû déjà savoir.
J’ai fixé ça. Voici comment.
Pourquoi les LLM n’ont pas de mémoire — et pourquoi c’est un choix délibéré
Voici où ça devient croustillant. La mémoire zéro des LLM n’est pas un oubli de conception — c’est une décision d’architecture.
Les modèles de langage fonctionnent avec une fenêtre de contexte : une quantité fixe de tokens qu’ils peuvent traiter à la fois. Claude 3.5 Sonnet gère jusqu’à 200 000 tokens dans une fenêtre. Impressionnant. Mais cette fenêtre se ferme dès que la session se termine. Tout disparaît.
Pourquoi ne pas simplement tout garder ? Deux raisons techniques majeures.
D’abord, le coût computationnel. Injecter des milliers de tokens de contexte dans chaque requête, pour chaque utilisateur, à chaque conversation — c’est économiquement non viable à l’échelle d’un service SaaS grand public.
Ensuite, la confidentialité. Stocker des conversations personnelles sur des serveurs tiers soulève des questions RGPD légitimes. La mémoire zéro est aussi une forme de protection des données.
Le problème : c’est vous qui payez le prix.
Retournons la situation. Si le modèle ne peut pas se souvenir, la solution n’est pas de lui demander de mémoriser — c’est de construire une couche de mémoire externe qui lui injecte le bon contexte au bon moment.
C’est exactement ce que fait une base vectorielle.
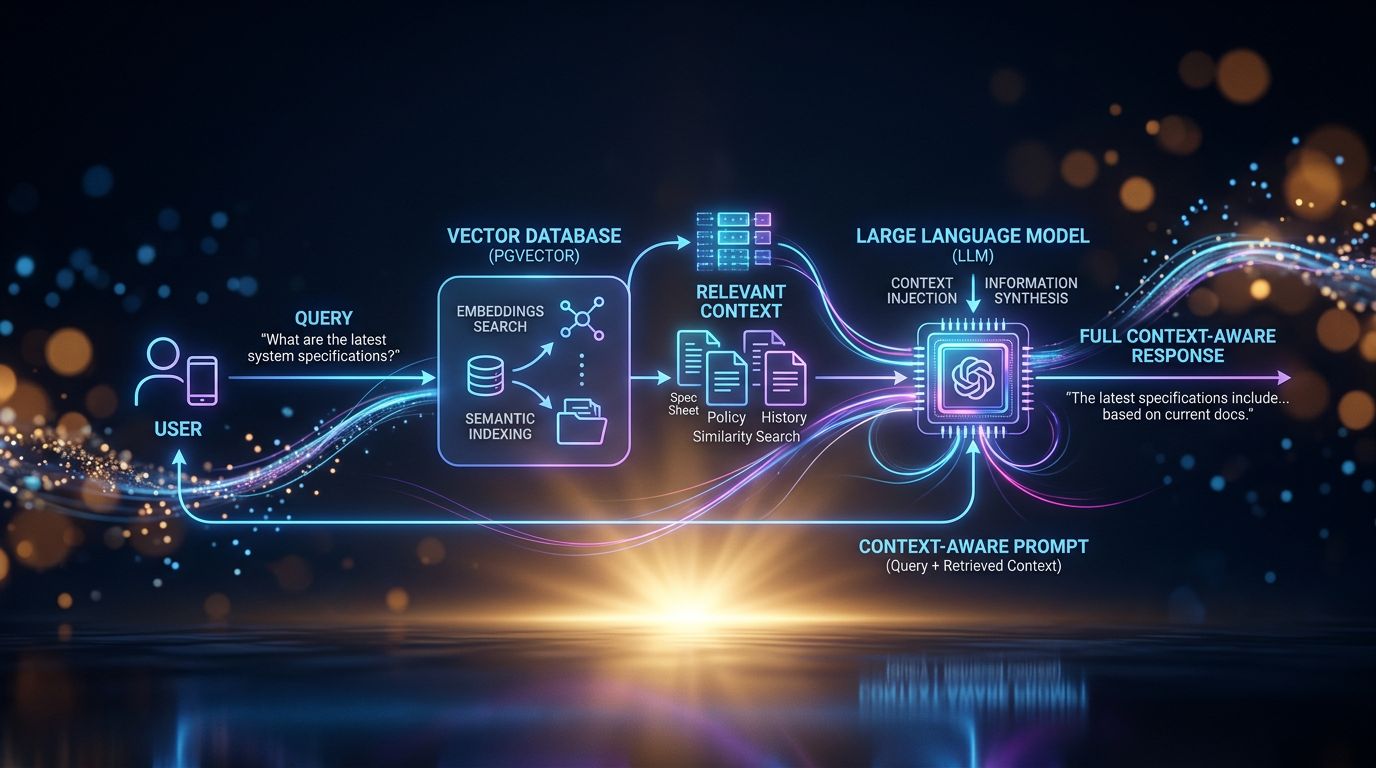
pgvector + embeddings : la stack qui donne une mémoire à votre IA
Ce qu’on ne vous dit jamais dans les articles “IA productivity tips” : la vraie différence entre un assistant IA basique et un assistant IA professionnel, c’est la couche de persistance.
Voici la stack concrète.
pgvector est une extension PostgreSQL qui permet de stocker et de rechercher des embeddings vectoriels. Un embedding, c’est la représentation mathématique d’un texte — une liste de nombres qui capture le sens sémantique du contenu. Deux phrases similaires auront des embeddings proches dans l’espace vectoriel.
Le workflow fonctionne ainsi : chaque information importante (fiche client, note de projet, préférence de communication, décision prise) est convertie en embedding et stockée dans pgvector. Quand vous posez une question, le système effectue une recherche sémantique — pas par mots-clés, par sens — et récupère les informations les plus pertinentes. Ces informations sont injectées dans le prompt avant que l’IA réponde.
Résultat : l’IA “sait” qui est votre client Bertrand sans que vous ayez besoin de le lui rappeler.
Ce n’est pas de la magie. C’est de l’ingénierie.
“La mémoire n’est pas une fonctionnalité de l’IA — c’est une fonctionnalité de l’infrastructure qui l’entoure.”
L’expérience m’a appris que la qualité de la mémoire dépend directement de la qualité des données stockées. Garbage in, garbage out. Si vos fiches clients sont vagues, votre IA sera vague. Si elles sont précises, structurées, à jour — votre IA devient un collaborateur qui connaît vraiment votre activité.
Ce que ça change concrètement pour un freelance ou une agence
Mon analyse révèle trois gains opérationnels majeurs, mesurables, concrets.
Le brief zéro. Fini le “rappelle-moi le contexte de ce projet”. L’assistant connaît déjà le client, son secteur, ses tics de langage, ses contraintes budgétaires, les décisions prises lors des trois dernières réunions. Vous arrivez directement à la valeur ajoutée.
La cohérence cross-sessions. Vous avez décidé en janvier de toujours envoyer les devis le jeudi. En mars, votre assistant s’en souvient encore. Pas parce qu’il est intelligent — parce que cette information est dans sa mémoire vectorielle, récupérée automatiquement quand le contexte l’exige.
Le travail asynchrone. Voici le point que peu de gens réalisent. Une IA avec mémoire persistante peut travailler pour vous quand vous n’êtes pas là. Analyser des patterns, préparer des briefs, détecter des opportunités dans votre CRM — parce qu’elle a le contexte nécessaire pour agir de manière pertinente.

Chiffrons. Sur 10 clients actifs, si vous économisez 8 minutes de contexte par interaction et que vous avez en moyenne 3 interactions IA par client par semaine — c’est 4 heures récupérées chaque semaine. 16 heures par mois. Soit 2 jours de travail par mois que vous pouvez facturer ou simplement ne pas travailler.
Le protocole MCP : piloter votre mémoire IA depuis Claude Desktop
Mais attention au piège. Avoir une base vectorielle, c’est bien. Pouvoir l’interroger naturellement depuis votre interface IA habituelle, c’est mieux.
C’est là qu’intervient le protocole MCP (Model Context Protocol), développé par Anthropic. MCP est un standard qui permet à des outils externes de s’intégrer directement dans Claude Desktop — en exposant des fonctions que Claude peut appeler de manière transparente pendant la conversation.
Concrètement : vous ouvrez Claude Desktop, vous posez une question sur le client Martine Dubois, et Claude interroge automatiquement votre base pgvector via MCP pour récupérer sa fiche, l’historique de vos échanges, les projets en cours. Tout ça sans que vous ayez à copier-coller quoi que ce soit.
36 outils MCP. C’est le nombre d’intégrations disponibles dans Nova-Mind pour piloter l’assistant depuis Claude Desktop. Gestion de projets, CRM, notes, tâches — tout accessible via langage naturel, avec la mémoire vectorielle en arrière-plan.
“Le meilleur workflow IA est celui que vous n’avez pas besoin de gérer activement.”
Ce qu’on ne vous dit jamais : MCP change la nature de l’interaction avec l’IA. On passe d’un chatbot qu’on interroge à un collaborateur qu’on mandate. La nuance est énorme sur le plan opérationnel.
Les trois erreurs classiques quand on essaie de donner de la mémoire à son IA
Voyons ça sous un autre angle. Après avoir observé des dizaines de freelances et d’agences tenter d’implémenter une mémoire IA, voici les patterns d’échec les plus fréquents.
Erreur 1 : stocker trop sans structurer. Balancer tous vos emails dans une base vectorielle ne crée pas de la mémoire — ça crée du bruit. La recherche sémantique retourne ce qui est proche, pas ce qui est important. La structure des données compte autant que leur volume.
Erreur 2 : négliger la mise à jour. Une mémoire qui ne se met pas à jour est pire qu’une mémoire zéro. L’IA va agir sur des informations obsolètes avec une confiance totale. Résultat : des erreurs contextuelles difficiles à détecter.
Erreur 3 : confondre mémoire et contexte de session. Injecter 50 000 tokens de contexte dans chaque prompt n’est pas de la mémoire — c’est de la surcharge. La vraie mémoire vectorielle est sélective : elle récupère uniquement ce qui est pertinent pour la requête en cours. C’est la différence entre un collaborateur qui sait tout et un collaborateur qui sait ce dont vous avez besoin maintenant.
Impact. Ces trois erreurs expliquent pourquoi la majorité des tentatives DIY de mémoire IA échouent ou restent anecdotiques.
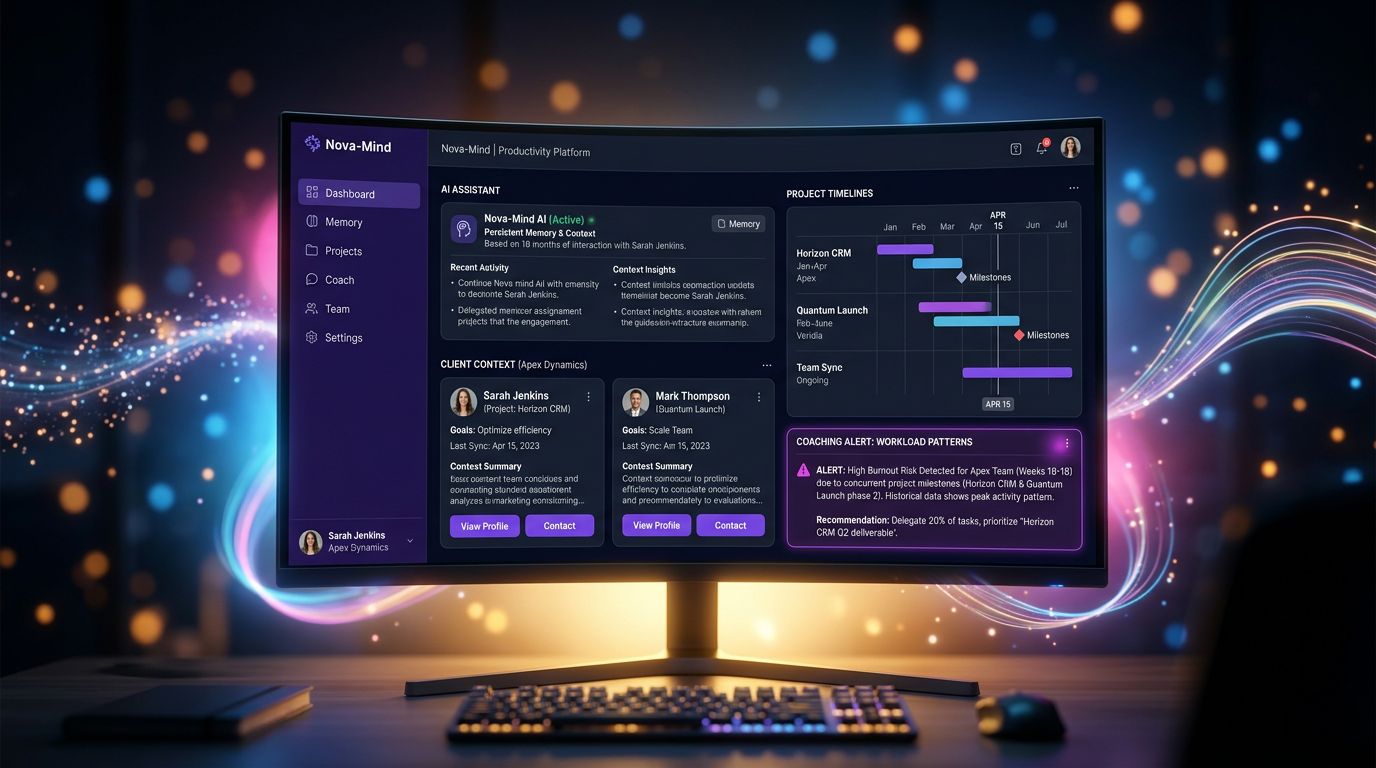
Ce que ça donne dans la pratique avec Nova-Mind
Concrètement, voici le workflow que j’ai construit et que j’utilise quotidiennement.
Chaque client a une fiche structurée dans le CRM — secteur, interlocuteurs, historique des projets, contraintes spécifiques, ton de communication préféré. Ces fiches sont vectorisées en temps réel dans pgvector via Supabase.
Quand j’interagis avec Nova (l’assistant IA intégré), elle interroge automatiquement cette base selon le contexte de ma question. Si je parle d’un projet web pour une PME industrielle, elle sait déjà que ce client préfère les livrables en PDF, qu’il a un budget serré sur la phase 2, et que son CTO est difficile à joindre le vendredi.
Le coaching proactif de Cerebro va plus loin : même quand je ne suis pas connecté, le système analyse mes patterns de travail, détecte si je suis en train de sous-estimer une charge de travail récurrente, et me prépare des suggestions contextuelles pour la prochaine session.
39€/mois. Données hébergées en privé sur Supabase. App desktop native sur macOS, Windows et Linux.
Ce n’est pas un gadget. C’est une infrastructure de travail.
Trois points à retenir avant de passer à l’action
Si vous deviez retenir trois choses de cet article :
-
La mémoire IA n’est pas une feature native des LLM — c’est une couche d’infrastructure à construire avec pgvector et des embeddings. Sans ça, vous ré-expliquez le contexte à l’infini.
-
La qualité prime sur la quantité — 20 fiches clients bien structurées valent mieux que 500 emails bruts dans une base vectorielle. La pertinence de la récupération dépend de la qualité des données.
-
MCP change la nature de l’interaction — passer d’un chatbot à un collaborateur contextualisé n’est pas un changement cosmétique, c’est un changement opérationnel qui se mesure en heures récupérées chaque semaine.
La prochaine étape
Vous avez deux options.
Construire vous-même la stack pgvector + embeddings + MCP. C’est faisable si vous êtes à l’aise avec PostgreSQL et les API d’embeddings. Comptez 2 à 3 semaines de configuration pour un résultat fonctionnel, et un maintien continu de l’infrastructure.
Ou utiliser Nova-Mind, où tout ça est déjà en place, intégré, et opérationnel dès le premier jour. La mémoire vectorielle, le protocole MCP, le CRM, la gestion de projets — dans un seul outil à 39€/mois.
Le choix dépend de votre appétence technique et de la valeur que vous accordez à votre temps.
Mais posez-vous cette question : combien valent 4 heures récupérées par semaine dans votre activité ?
Testez Nova-Mind et commencez à travailler avec un assistant qui se souvient enfin de tout.
Partager cet article
Réseaux sociaux
Analyser avec l'IA

Charles Annoni
Chef de projetCharles Annoni accompagne les entreprises dans leur développement sur le web depuis 2008.









