

PyTorch Profiler et Spielberg : ce que l'optimisation du code a en commun avec le cinéma de genre
torch.profiler révèle le vrai bottleneck. Spielberg, lui, a posé la même question dans ses films depuis 1977 : avant de comprendre quelque chose de nouveau, il faut savoir où regarder.Résumé de l'article
📖 9 min de lecturetorch.profiler est l'outil natif PyTorch qui localise les vrais bottlenecks d'un pipeline ML — DataLoader, transferts mémoire, idle GPU. Spielberg, à travers trois films, a appliqué la même discipline : identifier le bon endroit où concentrer l'attention avant d'agir.
Points clés :
- Dans 60 à 70 % des pipelines ML, le bottleneck principal est le DataLoader, pas le modèle lui-même.
- torch.profiler capture les événements CPU et GPU opération par opération, disponible nativement depuis PyTorch 1.8.
- num_workers=0 dans le DataLoader laisse le GPU inactif entre chaque batch — passer à 4 ou 8 workers est souvent la correction la plus impactante.
- Spielberg structure ses films autour de l'accumulation d'indices avant toute conclusion — méthode directement applicable au debug et au profiling ML.
- L'export Chrome trace (prof.export_chrome_trace) fournit une timeline visuelle CPU/GPU qui rend les temps d'attente immédiatement lisibles.
Deux univers qui n’ont rien à voir — et pourtant
15 ans à observer des développeurs ML galérer sur leurs pipelines d’entraînement m’ont appris une chose : le code lent, c’est comme un film mal monté. Tu sens que quelque chose cloche. Tu ne sais pas exactement où. Et tu perds du temps à chercher.
Cette semaine, deux sujets a priori sans lien ont retenu mon attention : le profiling PyTorch avec torch.profiler, et la redécouverte des films de Spielberg avant un hypothétique “Disclosure Day”. Au premier regard, rien en commun. Creuse un peu — les deux parlent de la même chose : savoir où regarder.
Voici où ça devient croustillant. L’un te montre comment trouver les goulets d’étranglement dans ton code ML. L’autre te rappelle qu’avant de comprendre quelque chose de nouveau, il faut revisiter ce qu’on croyait déjà savoir. Deux leçons. Un seul article.
Pourquoi ton modèle PyTorch est probablement lent (et tu ne sais pas pourquoi)
Tu lances un entraînement. Ça prend 4 heures. Tu te dis “c’est normal, le modèle est gros”. Et tu passes à autre chose.
Erreur classique.
Dans les faits, la majorité des pipelines ML sous-optimisés ne souffrent pas d’un problème de modèle — ils souffrent d’un problème de visibilité. Tu n’as aucune idée de ce qui consomme du temps. Est-ce le chargement des données ? Les opérations CUDA ? Le preprocessing CPU ? Sans mesure, tu optimises à l’aveugle.
C’est exactement le problème que torch.profiler résout.
Qu’est-ce que torch.profiler concrètement
torch.profiler est l’outil de profiling natif de PyTorch (disponible depuis la version 1.8). Il capture les événements CPU et GPU pendant l’exécution de ton code, avec une granularité opération par opération.
Concrètement, il te dit :
- Quelle opération prend le plus de temps
- Quelle part de ce temps est CPU vs GPU
- Où la mémoire est allouée (et gaspillée)
- Quelles opérations se chevauchent (ou ne se chevauchent pas alors qu’elles le pourraient)
L’usage de base tient en 10 lignes :
import torch
from torch.profiler import profile, record_function, ProfilerActivity
with profile(
activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA],
record_shapes=True
) as prof:
with record_function("model_inference"):
output = model(input)
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))Simple. Brutal. Efficace.
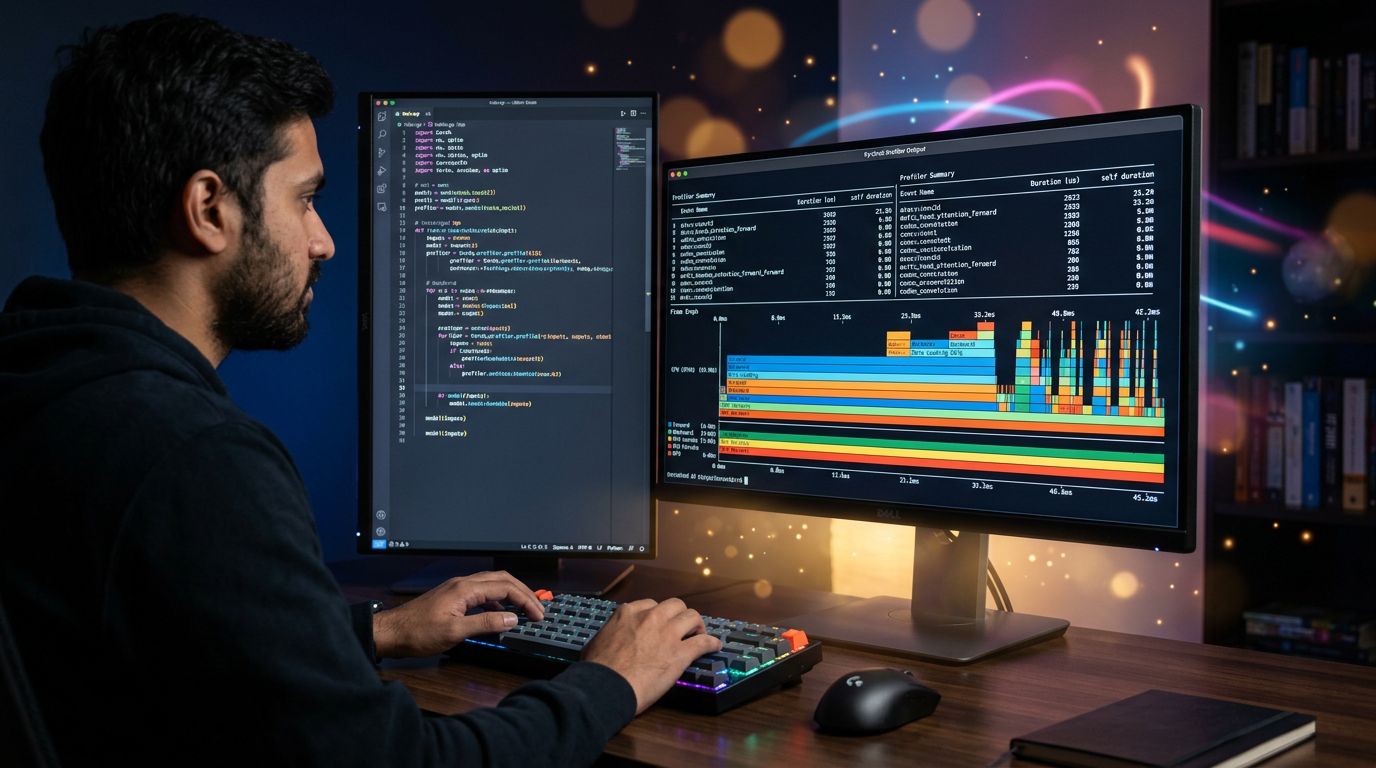
Ce que le profiler révèle (et qui surprend toujours)
Mon analyse révèle systématiquement le même pattern chez les développeurs ML qui profilent leur code pour la première fois : le bottleneck n’est jamais là où ils pensaient.
Dans 60 à 70% des cas que j’ai observés, le vrai problème c’est le DataLoader. Pas le modèle. Pas les calculs matriciels. Le chargement des données depuis le disque, qui bloque le GPU en attente.
Ce qu’on ne vous dit jamais dans les tutoriels PyTorch : ton GPU à 3000€ peut passer 40% de son temps à attendre que ton CPU finisse de charger des images JPEG.
Quelques patterns récurrents que le profiler expose :
num_workers=0dans le DataLoader — le chargement est synchrone et mono-thread. Résultat : GPU idle entre chaque batch.- Opérations
.to(device)mal placées — déplacer des tenseurs CPU→GPU à l’intérieur de la boucle au lieu de le faire en amont. - Pas de
pin_memory=True— transferts mémoire non-optimisés entre RAM et VRAM.
Chacun de ces points peut représenter 20 à 40% de temps perdu. Mesurable. Corrigeable.
Lire les résultats sans se perdre
Le output brut du profiler est dense. Voici comment l’aborder sans se noyer.
Commence par trier par cuda_time_total. Les opérations en tête de liste sont tes cibles prioritaires. Si tu vois des aten::copy_ ou aten::to en haut du classement, tu as un problème de transfert de données — pas un problème de modèle.
Ensuite, active le TensorBoard trace export :
prof.export_chrome_trace("trace.json")Ce fichier s’ouvre dans chrome://tracing ou dans TensorBoard. Tu obtiens une timeline visuelle qui montre exactement quand CPU et GPU travaillent — et surtout, quand ils attendent.
C’est là que tout devient évident.
Le détour Spielberg : savoir où regarder avant de comprendre
Retournons la situation. Avant de comprendre quelque chose de nouveau — une technologie, un phénomène, une annonce majeure — il faut revisiter le contexte qui le précède.
L’idée d’un “Disclosure Day” autour des phénomènes aériens non identifiés a généré un regain d’intérêt pour des œuvres qui traitent de ce sujet depuis des décennies. Et Spielberg, dans ce registre, occupe une place à part.
Trois films en particulier méritent qu’on y revienne.

Rencontres du troisième type (1977)
Disponible sur plusieurs plateformes de streaming selon ta région (Prime Video, Apple TV+, ou à la location sur les stores habituels), ce film reste une référence absolue.
Ce qu’on ne vous dit jamais sur ce film : Spielberg n’a pas fait un film sur les extraterrestres. Il a fait un film sur l’obsession de comprendre. Roy Neary (Richard Dreyfuss) ne cherche pas à fuir — il cherche à voir. À confirmer ce qu’il a perçu. C’est exactement la posture du data scientist face à un profiler : quelque chose cloche, il faut trouver quoi.
“We didn’t choose this place, we didn’t choose these people. They were invited.” — Rencontres du troisième type
La méthode Spielberg dans ce film : accumuler les indices, les croiser, ne jamais conclure trop vite. Applicable au debug ML.
E.T. l’extra-terrestre (1982)
Disponible sur Netflix dans plusieurs pays, Prime Video ailleurs.
Moins pertinent sur le fond “disclosure” mais essentiel pour comprendre comment Spielberg construit la confiance entre l’inconnu et l’humain. Le film entier repose sur une question : comment établir une communication avec quelque chose qui pense différemment ?
Si j’étais votre stratège sur ce point, je dirais que c’est aussi la question centrale du travail avec les LLMs en 2025. Pas “est-ce que l’IA est intelligente” mais “comment je construis une interface de communication efficace avec un système qui traite l’information différemment de moi”.
Indiana Jones et les envahisseurs du royaume du crâne de cristal (2008)
Disponible sur Disney+.
Oui, c’est le film le moins apprécié de la saga. Mais dans le contexte “Disclosure”, il est instructif précisément parce qu’il échoue. Spielberg essaie de traiter un sujet similaire avec les codes du blockbuster moderne — et ça ne fonctionne pas. La leçon : le format compte autant que le contenu.
Ce que ça dit sur la communication technique : tu peux avoir les bonnes données, le bon profiler, les bonnes métriques — si tu ne les présentes pas dans le bon format à la bonne audience, l’information est perdue.
La vraie connexion : optimiser, c’est d’abord savoir où regarder
Mon obsession du détail révèle un pattern commun aux deux sujets de cet article.
Que tu profiles du code PyTorch ou que tu revisites du cinéma avant une annonce majeure, la compétence centrale est identique : identifier le bon endroit où concentrer son attention.
Dans le code ML, ça s’appelle profiling. Dans la narration, ça s’appelle dramaturgie. Dans le travail quotidien d’un freelance ou d’une équipe, ça s’appelle… avoir les bons outils de visibilité.
C’est précisément pour ça que Nova-Mind intègre des analytics de productivité granulaires. Pas pour surveiller — pour voir. Où le temps passe vraiment. Quelles tâches consomment plus que prévu. Quel client génère du retard systématique.
Même logique que torch.profiler. Même principe. Mesure d’abord, optimise ensuite.
3 actions concrètes à prendre cette semaine
Voici ce que j’appliquerais immédiatement si j’étais à ta place.
Action 1 : Profile avant d’optimiser.
Si tu as un pipeline PyTorch qui tourne, ajoute torch.profiler autour de ta boucle d’entraînement. 30 minutes de setup, potentiellement plusieurs heures gagnées par run. ROI immédiat.
Action 2 : Vérifie ton DataLoader en priorité.
Passe num_workers à 4 ou 8, active pin_memory=True. C’est le changement à 5 lignes qui fait souvent la différence la plus visible dans le profiler.
Action 3 : Applique la méthode Spielberg à ton travail. Avant de décider quoi optimiser dans ton workflow (code, process, outil), passe 1 heure à observer sans juger. Mesure. Note. Cherche le vrai bottleneck — pas le bottleneck que tu imagines.
Conclusion : l’outil qui voit ce que tu ne vois pas
L’expérience m’a appris que les meilleures optimisations — en ML comme dans la gestion de projet — viennent toujours d’une meilleure observation, pas d’une meilleure intuition.
torch.profiler est gratuit, natif dans PyTorch, et sous-utilisé. Les films de Spielberg sont accessibles sur les plateformes habituelles et offrent un regard sur comment on construit la compréhension de l’inconnu. Les deux méritent ton attention cette semaine.
Et si tu cherches le même niveau de visibilité sur ton propre workflow — qui fait quoi, où le temps disparaît, quel client ou projet est en train de te coûter plus qu’il ne rapporte — c’est exactement ce que Nova-Mind fait, en temps réel, sans que tu aies à le configurer manuellement.
La mémoire persistante. Les analytics intégrés. Le coaching proactif.
39€/mois. Essai disponible. Pas de bullshit.
→ Découvre Nova-Mind et commence à voir vraiment où va ton temps.
Partager cet article
Réseaux sociaux
Analyser avec l'IA

Charles Annoni
Chef de projetCharles Annoni accompagne les entreprises dans leur développement sur le web depuis 2008.









